So continuing with Topic Modeling…(see earlier post)
Well -the time had come to confront pubmed- the real data I was going to work with. To start with I decided to only use 2013 pubmed data to see if I could run LDA on it and get out meaningful topics. Well, what do I mean by pubmed data: As I explained earlier, pubmed is a repository containing almost *all* research literature pertaining to the biomedical field. Since it is maintained and funded by NIH, we as the tax payers can access or scrape data from it! The only caveat is that only a small subset of papers have the entire text, and they are housed in what is called Pubmed Central. For the rest of the data we can access things like: title, abstract, keywords (if any), journal name, journal ISSN number, date of publication, date created, date last modified etc.
In preparing the text corpus for LDA, we decided to use only the title and abstract. So, for all the records published in 2013, I parsed out the title and abstract, and created a text corpus containing one record per line, with the pmid as the record identifier. It looked something like this:
The real challenge for LDA is figuring out how many topics or categories should you try to divide the corpus into. I played around with K=10,12,14…500. It seemed to me that the larger the K, more “fine” grained my topics: but was there an “intrinsic” number of topics that pubmed was naturally divided into… but remember each paper or record has a non zero probability of belonging to every topic- its a mixture of topics. So we could think about each “topic” as a dimension, and each paper belonging to this K dimensional space. And intuitively I felt that we went with a really large K, we would get a really high resolution among topics (which we could think of as subtopics)- and then if we ran hierarchical clustering on this large number of topics, we could “cluster” similar topics thus naturally forming the “super topics”. I was excited. The challenge was that as K grew large, so did my job of trying to make sure that indeed all the topics made sense.
The road was quite bumpy. For example, I initially included keywords along with the abstracts in the text corpus, but found that keywords were present only in about 30% of the papers!. Earlier I had thought that perhaps the keywords could make up the main “vocabulary” of the corpus and be used to describe it- but that did not seem to be the case. Furthermore, in many cases the keyword tended to be names of particular chemical compounds which could not really “describe” the paper. I also had to check and see if the topics made sense. One way to do this was, for a given value of K, to look at the top 20 words of the topic and see if the words seem to point to a coherent topic. If so, then pull out all the papers that had a high probability of being assigned to that topic (say >0.7) and look at them.
To see how good my topic modeling really was, I decided to ask the inverse question: if I picked specific journals ( that I know were represented in the corpus) , pulled out all the papers from journals, and summed the topic probabilities of those papers, I would get a “topic distribution” for that set of journals. What did that look like? I decided to pick specialized journals like “Cancer”, “Oncology Letters”, “Oncoimmunology”, OncoTargets (which could represent a specific topic “cancer”) and The Science of the total environment, Environmental pollution, Environmental toxicology and pharmacology, and Environmental toxicology and chemistry which could be thought to represent “environmental science”.
Figure A below is the topic distribution for the journal “Cancer“. As you can see topic 13 has avery high representation. Figure B shows the topic distribution if papers published in Oncology Letters”, “Oncoimmunology” and “OncoTargets” are included. You can see, topic 13 continues to have a high representation, but representation for topic 3 has also gone up.
Figure A . 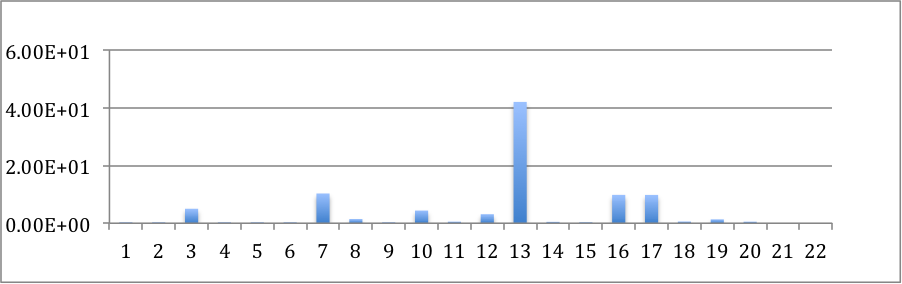
Figure B. 
So what are topic 13 and topic 3? Here are word cloud representations of their top most words:
 topic 13 topic 3
topic 13 topic 3
These word clouds make sense given that the journals were Cancer, Oncology letters etc; the high representation of topic 13 is very heartening.
Figure C. below is the topic distributions for the journal The Science of the total environment, and Figure D is the topic distribution for papers from journals The Science of the total environment, Environmental pollution, Environmental toxicology and pharmacology, Environmental toxicology and chemistry. Topics 4 and 2 are the most dominant.
Figure C. 
Figure D. 
And here is the word clouds for topics 4: 
As you can see it doesn’t conjure up the topic “environmental science”. But then the question is, is the value of K too small to “resolve” the topic “environmental science”? we can look at what happens when K is larger. Figure E shows the distribution of the same papers as included in Figure D, but assuming that we have run lda with K=50 on them.

As you can see, it topic 15 that dominates. Here is the word cloud for topic 15 and this looks much more like environmental science!!
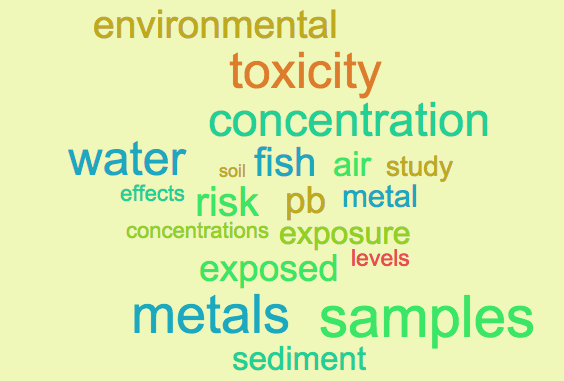
So what value of K( ie number of topics) should we go with? After conducting many experiments like these, we decided to go with K=150. Yes, K=150 is a large number but the thinking was that we could run the hierarchical clustering on the topics themselves and see if how they clustered together and then each cluster could be considered a “supertopic” or category and the topics that were contained in it, would be the finer classification. On the other hand 150 was manageable , in case we needed to perform some manual curation.
