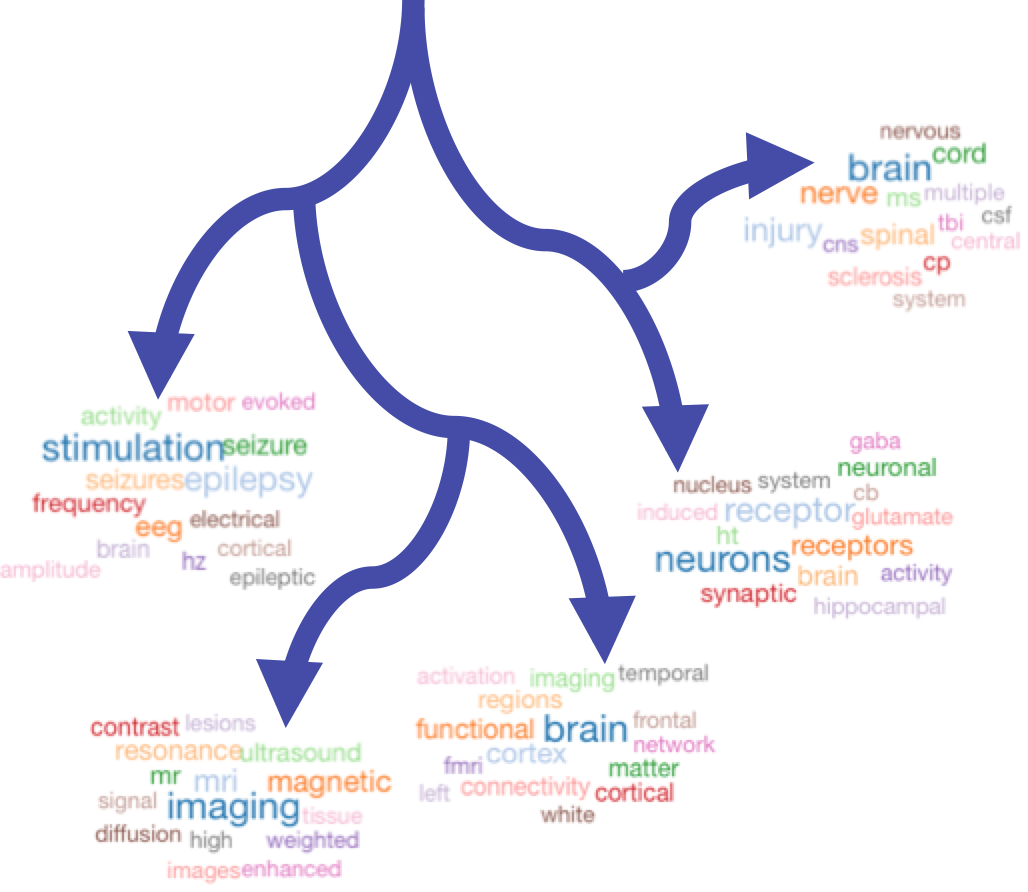
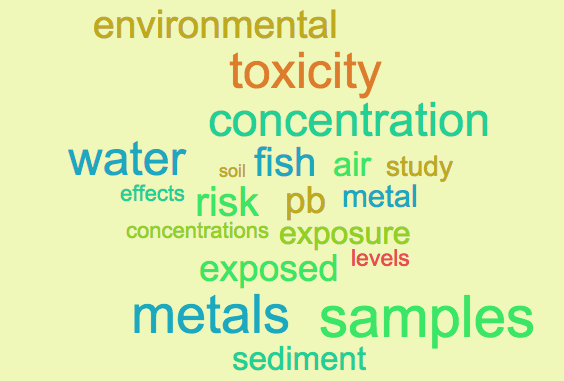
As the project grew, we started downloading tweets from various journal websites and tried to set up an algorithm to parse tweets that were related to particular papers and link them to the paper; thereby producing another “metric” to compare papers by. In addition; we started keeping a detailed records all the authors of the papers and attempted to create a citation database. As complexity grew; we found that our local server was too slow and after some research; decided to take the plunge and move our stuff to AWS-the Amazon Web Server. We created a VPC (a virtual Private cloud), moved our database to Amazon’s RDS (Relational Database Service) and created buckets or storage on Amazon’s S3 (Simple Storage Service). Its relatively easy to do and the AWS documentation is pretty good. What I found really helpful were the masterclass webinar series.
I launched a Linux based instance and then installed all the software versions I needed like python2.7, pandas, numpy, ipython-pylab, matplotlib, scipy etc . It was interesting to note that on many of the amazon machine, the default python version loaded was 2.6, not 2.7. I scouted the web a fair bit to help me configure my instance the am sharing soem of the commands below
General commands to install python 2.7 on AWS- should work on most instances running Ubuntu/RedHat Linux:
Start python to check the installation unicode type. If you have to deal with a fair amount of unicode data like I do then make sure you have the “wide build” . I learned this the hard way.
- >>import sys
- >>print sys.maxunicode
It should NOT be 65564
- >>wget https://s3.amazonaws.com/aws-cli/awscli-bundle.zip
- >> unzip awscli-bundle.zip
- >> sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
- # install build tools
- >>sudo yum install make automake gcc gcc-c++ kernel-devel git-core -y
- # install python 2.7 and change default python symlink
- >>sudo yum install python27-devel -y
- >>sudo rm /usr/bin/python
- >>sudo ln -s /usr/bin/python2.7 /usr/bin/python
- # yum still needs 2.6, so write it in and backup script
- >>sudo cp /usr/bin/yum /usr/bin/_yum_before_27
- >>sudo sed -i s/python/python2.6/g /usr/bin/yum
- #This should display now 2.7.5 or later: >>python
- >>sudo yum install httpd
- # now install pip for 2.7
- >>sudo curl -o /tmp/ez_setup.py https://bitbucket.org/pypa/setuptools/raw/bootstrap/ez_setup.py
- >>sudo /usr/bin/python27 /tmp/ez_setup.py
- >>sudo /usr/bin/easy_install-2.7 pip
- >>sudo pip install virtualenv
- >>sudo apt-get update
- >>sudo apt-get install git
- # should display current versions: pip -V && virtualenv –version
- Installing all the python library modules:
- sudo pip install ipython
- sudo yum install numpy scipy python-matplotlib ipython python-pandas sympy python-nose
- sudo yum install xorg-x11-xauth.x86_64 xorg-x11-server-utils.x86_64
- sudo pip install pyzmq tornado jinja2
- sudo yum groupinstall “Development Tools”
- sudo yum install python-devel
- sudo pip install matplotlib
- sudo pip install networkx
- sudo pip install cython
- sudo pip install boto
- sudo pip install pandas
- Some modules could Not be loaded using pip, so use the following instead: >>sudo apt-get install python-mpi4py python-h5py python-tables python-pandas python-sklearn python-scikits.statsmodels
- Note that to install h5py or pytables you must install the following dependencies first:
- -numpy
- -numexpr
- -Cython
- -dateutil
- HDF5
- HDF5 can be installed using wget:
- >> wget http://www.hdfgroup.org/ftp/HDF5/current/src/hdf5-1.8.9.tar.gz
- >>tar xvfz hdf5-1.8.9.tar.gz; cd hdf5-1.8.9
- >> ./configure –prefix=/usr/local
- >> make; make install
- Pytables
- pip install git+https://github.com/PyTables/PyTables.git@v.3.1.1#egg=tables
**to install h5py make sure hdf5 is in the path.
I really liked the concept of AMI’s : you create a machine that has the configuration that you want and then create an “image” and can give it a name. You have then created a virtual machine that you can launch anytime you want and as many copies of as you want! What is also great is that when you create the image, all the files that may be in your directory at that time are also part of that virtual machine …so its almost like you have a snapshot of your environment at the time. So create images often (you can delete old images ofcourse!) and you can launch your environment at any time. Of course you can and should always upload new files to S3 as that it you storage repository.
Another neat trick was to learn that if you can install EC (Elastic Cloud) CLI(Command Line Interface) on your local machine, and set up your IAM you don’t need the you don’t need the .pem file!! Even if you are accessing an AMI in a private cloud; when you set up the instance make sure you click on “get public IP” when you launch your instance and log in as ssh –Y ubuntu@ ec2-xx.yyy.us-west1.compute.amazonaws.com. You can them enjoy xterm and the graphical display from matplotlib, as if you are running everything on your local terminal. Very cool indeed!