(continued from Topic Modeling …)
So great, I ran LDA, got 150 topics, and now I wanted to see if one could group these topics together using clustering. How can one go about doing that? Well as part of the process, LDA basically creates a “vocabulary” consisting of all the words from the corpus. As this number may get unmanageably large, as part of the LDA preprocessing, one removes words like a, an, the, if where (also called stopwords) as may not really help decide whether a document belongs to a certain topic or not. There are other text learning tricks like stemming and lemmatization that I thought were not necessarily useful this context, but can often be useful and help control the size of the vocabulary. Well the vocabulary from my run contained ~650,000 words and mallet allows you to output, for every topic, the word counts for all these words! So now you have a representation of all the topics in terms of their “word vectors”! And one can use this word vector to calculate “distances” between topics.
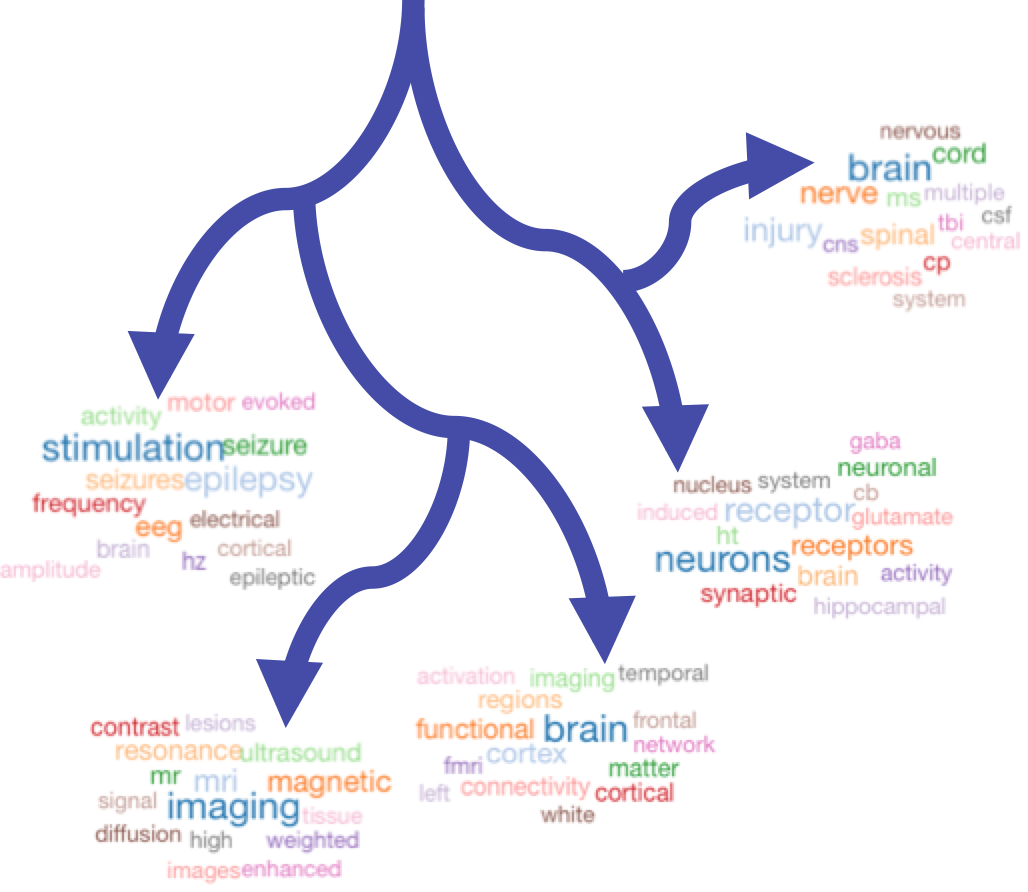
So after some data wrangling and manipulation, I had the topics represented in a numerical matrix, and ran the clustering algorithm on them. There are many variations of hierarchical clustering algorithms, and I tried most them to see which one seemed the best. I finally went with average linkage and shown below are some of the branches that clustered together. Instead of showing, topic numbers as leaves, we are displaying the word cloud represented by the topic at that leaf:
Figure on the left could be thought to represent a neuroimaging cluster and the figure to the right could be thought to represent disease and trauma. These images are courtesy Natalie Tellis- Thanks Natalie!!


Unfortunately, we had to do a significant amount of manual curation, as some of the clusters didn’t make sense the way we humanly think of these topics …though algorithmically speaking they probably were “sisters”. We wound up having twenty supertopics or umbrella topics which contained the topics that LDA had produced. The naming of topics was done manually and was strongly influenced by the top most words for that topic.
For example the supertopic called “Genetics and Genomics”, and “cellBiology” have the following subtopics: